
Co pierwsze: robots.txt czy META
Artykuły20 lutego 2018
Na jednej z grup na Facebooku pojawiła się ciekawa dyskusja na temat, który niektórym sprawia nie lada problem. Chodzi mianowicie o to, czemu strona z zablokowanym dostępem w pliku robots.txt pojawia się w indeksie. Zacznijmy więc od uporządkowania sobie najważniejszych informacji na ten temat, co postaram się opisać wręcz łopatologicznie.
Co pierwsze? Zapisy w pliku robots.txt czy te w sekcji META?
Zapisy w logach serwera (pełne zapisy o całej aktywności na stronie) pozwolą nam to sprawdzić i łatwiej zrozumieć. Oto ich fragment, na którym widać jedynie wybrane zapisy związane z aktywnością różnych robotów wyszukiwarek:
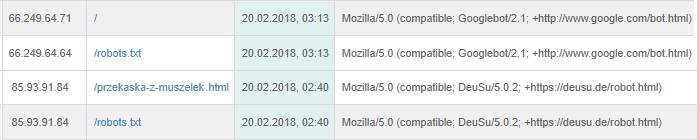
Jak widać, jeden z robotów wszedł do pliku robots.txt o godz. 2:40, a chwilę później zaczął przemierzać serwis, zaczynając od podstrony z jednym z przepisów opublikowanych na blogu. Potem do tego samego pliku zerknął Googlebot, aby sprawdzić, czy ma pozwolenie na dostęp do serwisu. Następnie wszedł na stronę główną, co również widać na załączonym obrazku, a potem zaczął "chodzić" po wybranych podstronach - tego już nie załączałam.
Mówiąc wprost, pierwsze co ma obowiązek zrobić robot wyszukiwarki (w tym Googlebot) to sprawdzić, czy ma pozwolenie na dostęp do zawartości strony. Mówiąc o dostępie (zapis Allow: lub Disallow:) mam na myśli, czy może "zobaczyć" co znajduje się na stronie, a nie to, czy może ją zaindeksować/wyświetlić w wynikach wyszukwania. Możliwe są 3 sytuacje:
- robot ma pozwolenie na dostęp do całej strony - uzyskuje je w przypadku, gdy ALBO w pliku robots.txt znajduje się zapis Allow: / ALBO plik jest pusty lub w ogóle go nie ma, ponieważ jeśli roboty nie trafią na żadne blokady, to oznacza to, że mogą śmiało wejść gdziekolwiek chcą;
- robot ma zablokowany dostęp do całej strony - o takim zakazie mówi zapis Disallow: / po którym można wpisać albo nazwę wybranego robota, albo gwiazdkę, która dotyczy ich wszystkich;
- robot ma zablokowany dostęp tylko do wybranych podstron - oto przykładowy zapis w pliku robots.txt Blokuje on dostęp wszystkich robotów (mówi o tym gwiazdka przy User-Agent) tylko do wybranych podstron lub sekcji (np. cały folder /wp-includes), które zostały wymienione w poszczególnych wierszach po Disallow:
User-Agent: * Disallow: /wp-content/plugins Disallow: /wp-includes Disallow: /wp-admin Disallow: /*?s= Disallow: /*?replytocom= Disallow: /*pdf
Na wszystkie pozostałe podstrony robot może wejść i sprawdzić/przeczytać/zobaczyć ich zawartość, i na tym kończy się jego rola. Dopiero zapisy w sekcji META mówią o tym, czy strona może się wyświetlać w wynikach wyszukiwania.
Jeśli sekcja META NIE zawiera zakazu indeksacji, wtedy robot może spokojnie wyświetlić w indeksie dany wynik wraz z pobranym tytułem, opisem, a w przypadku braku zakazu wyświetlania kopii, również z linkiem do zapisanej kopii strony. ALE jeśli w sekcji META znajduje się zapis noindex lub none (czyli noindex + nofollow), to robot może zobaczyć zawartość strony, ale nie może jej wyświetlić w wyszukiwarce (np. Google).
Natomiast jeśli zaindeksowana została podstrona z zablokowanym dostępem w pliku robots.txt, wynik będzie wyglądał jak niżej. Może się tak zdarzyć, jeśli wynik był już zaindeksowany i z czasem została dodana blokada dostępu, albo jeśli podstrona została zaindeksowana ze względu na to, że roboty trafiały na nią przez znalezione linki.
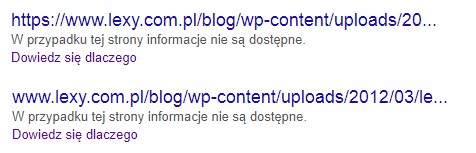
Po kliknięciu w link "Dowiedz się więcej" jesteśmy przekierowywani do artykułu pomocy Google, który wyjaśnia, że "Google nie udało się uzyskać dostępu do strony, by utworzyć opis do wyświetlenia w wynikach wyszukiwania".
Podsumowując - strona, do której dostęp dla robotów wyszukiwarek jest otwarty w pliku robots.txt, ALE która jednocześnie ma zapis noindex w sekcji META, nie może się wyświetlić w wyszukiwarce, jednak robot może do woli chodzić po stronie, niekoniecznie po tych sekcjach, na które chcielibyśmy skierować jej ruch. Natomiast strona, do której dostęp został zablokowany w pliku robots.txt, może (ale nie musi) zostać wyświetlona w Google, ale bez informacji pobranych z zawartości strony, czyli bez tytułu, zajawki oraz bez linka do kopii strony.
A zatem jaka jest główna różnica pomiędzy blokadą w robots.txt a zapisem noindex w sekcji META? Porównanie pół-żartem pół-serio dla łatwiejszego zapamiętania ;)
Zapis w pliku robots.txt mówi o tym, czy i do jakiej zawartości robot może się dostać. Z kolei zapisy w sekcji META mówią m.in. o tym, czy strona może zostać wyświetlona w wynikach wyszukiwania, czy też nie (noindex).
Dla jasnego porównania, najpierw robot puka do drzwi i pyta, czy może wejść do naszego domu, a my pozwalamy mu na to, ale z wykluczeniem (Disalow: w pliku robots.txt) sypialni ;) Wchodzi do domu do różnych pomieszczeń za wyjątkiem sypialni i pyta (sekcja META), czy może innym opowiedzieć o tym, co mamy w domu, zrobić zdjęcia i wyświetlić to wszystko w ogłoszeniu czy też w swoich statystykach. Jeśli się na to zgodzimy, to wyświetli w ogłoszeniu wybrane dane na temat wszystkich pomieszczeń za wyjątkiem sypialni, do której nie ma dostępu, więc nie ma jak zobaczyć, co tam się znajduje i czy może wyświetlić ją na swojej liście, czy też nie. Jeśli się nie zgodzimy (noindex), wszystkie informacje będzie musiał zostawić dla siebie, ale będzie mógł w statystykach zapisać nasz adres, byleby nie wyświetlić przy nim żadnych danych na temat mieszkańców ani wyglądu pomieszczeń. To będzie zapis w pełni anonimowy ;)
Z blokady w robots.txt najlepiej korzystać, aby sterować ruchem robotów i np. zapobiec traceniu ich czasu na przemierzanie zasobów. Analogicznie do naszego przykładu, jeśli chcemy dobrze zaprezentować gościom nasze mieszkanie i skupić się tylko na tym, co najciekawsze, nie musimy pokazywać bałaganu w garderobie czy pralni ;) a jeśli nawet pokażemy, to poprosimy, aby zostawić to dla siebie (noindex) i nigdzie o tym nie pisać. Bałaganem na stronie mogą być więc np. wyniki wyszukiwania czy sortowania, dlatego jeśli zablokujemy robotom dostęp do nich, nie będą w stanie zorientować się, że wyniki te prezentują prawie tę samą zawartość. Nawet jeśli ich adresy zostaną wyświetlone w wynikach wyszukiwania, nie będą stanowić problemu w kwestii duplikacji treści.
Krótkie zakończenie
Blokadę w pliku robots.txt stosujmy, jeśli nie chcemy, aby roboty wyszukiwarek traciły czas na przemierzanie wskazanych adresów, tylko skupiły się na najważniejszych dla nas podstronach. Wtedy co najwyżej w wynikach wyszukiwania wyświetli się anonimowy wynik. Z sekcji META korzystajmy na tych podstronach, które absolutnie nie mogą zostać zaindeksowane ani wyświetlane w wynikach wyszukiwania nawet w postaci pustych adresów.
Niestety dwóch pieczeni na jednym ogniu nie upieczemy, ponieważ nie można jednocześnie zabezpieczyć się przed dostępem robotów i zablokować przed indeksacją. Problem wynika z tego, że jeśli ustawimy blokadę w pliku robots.txt, to robot nie dotrze do zawartości pliku i nie odczyta zapisów w sekcji META.
 Marta Gryszko
Marta Gryszko