
Błędy serwera i ich znaczenie w SEO
Artykuły31 marca 2026
Błędy serwera a SEO – co każdy kod HTTP mówi Googlebotowi
Serwer jest składnikiem strony internetowej, który większość właścicieli serwisów dostrzega dopiero wtedy, gdy zaczyna sprawiać problemy. Przez lata pracy przy technicznym SEO zauważam, że konfiguracja serwera i obsługa kodów HTTP to obszar, który potrafi całkowicie rozłożyć organiczne wyniki serwisu — i to bez żadnego widocznego sygnału w postaci manualnej kary w Search Console. Wszystko dzieje się po cichu, na poziomie komunikacji między maszyną a robotem indeksującym.
To co warto zaznaczyć na samym początku : problemem nie jest sam fakt, że błędy się zdarzają. Zdarzają się zawsze. Problemem jest brak wiedzy o tym, jak Googlebot interpretuje każdą z odpowiedzi serwera i jakie decyzje na tej podstawie podejmuje względem indeksu.
Kod zanim treść
Każde żądanie HTTP — nieważne, czy wysyła je przeglądarka użytkownika, czy robot Google — kończy się odpowiedzią serwera zawierającą trójcyfrowy kod statusu. Ten kod jest pierwszą informacją, jaką Googlebot przetwarza, zanim zobaczy jakikolwiek fragment treści strony. Na jego podstawie bot decyduje, co zrobić z danym adresem URL: zaindeksować, odłożyć na później, usunąć z indeksu, a może w ogóle przestać o nim pamiętać.
Kody dzielą się na pięć klas: 1xx (informacyjne, rzadko istotne dla SEO), 2xx (sukces), 3xx (przekierowania), 4xx (błąd po stronie klienta) i 5xx (błąd po stronie serwera). W codziennej pracy SEO zdecydowana większość przypadków dotyczy klas 4xx i 5xx — i to właśnie na nich warto skupić uwagę.
Klasa 4xx, czyli zasób nie istnieje — z różnych powodów
404 — najczęstszy i najbardziej nierozumiany
Kod 404 mówi Googlebotowi, że żądany zasób nie istnieje pod wskazanym adresem. Tyle teoria. W praktyce sam fakt pojawienia się 404 nie powinien wywoływać paniki — to poprawna odpowiedź serwera dla adresów, których naprawdę nie ma. Problem zaczyna się wtedy, gdy 404 dotyczy adresów, które powinny istnieć, albo gdy jest ich na tyle dużo, że zaczynają wpływać na crawl budget.
Googlebot nie usuwa stron z indeksu po pierwszym natrafieniu na 404. Wraca do danego adresu kilkakrotnie w kolejnych tygodniach, żeby upewnić się, że zasób faktycznie zniknął na stałe. Dopiero po kilku potwierdzonych odmowach URL trwale znika z indeksu — zazwyczaj zajmuje to od kilku tygodni do kilku miesięcy, zależnie od tego, jak często robot odwiedza daną domenę.
Największy praktyczny problem z 404 to migracje serwisu, w których programiści zmieniają strukturę URL bez wdrożenia przekierowań. Każda zmieniona ścieżka generuje 404, strony tracą autorytet linkowy, który przez lata zbierały z zewnętrznych odnośników, i — co często pomijane — Googlebot marnuje część crawl budgetu na skanowanie adresów, które już niczego nie zawierają. W serwisach z milionami podstron to może realnie wpłynąć na szybkość indeksowania nowych treści.
Żeby sprawdzić skalę problemu: raport „Strony" w Google Search Console, filtr „Nie zaindeksowano – błąd 404". Warto przejrzeć te adresy pod kątem historycznego ruchu i linków przychodzących — te dwa czynniki najszybciej pokażą, gdzie rzeczywiście jest pożar, a gdzie tylko kurz.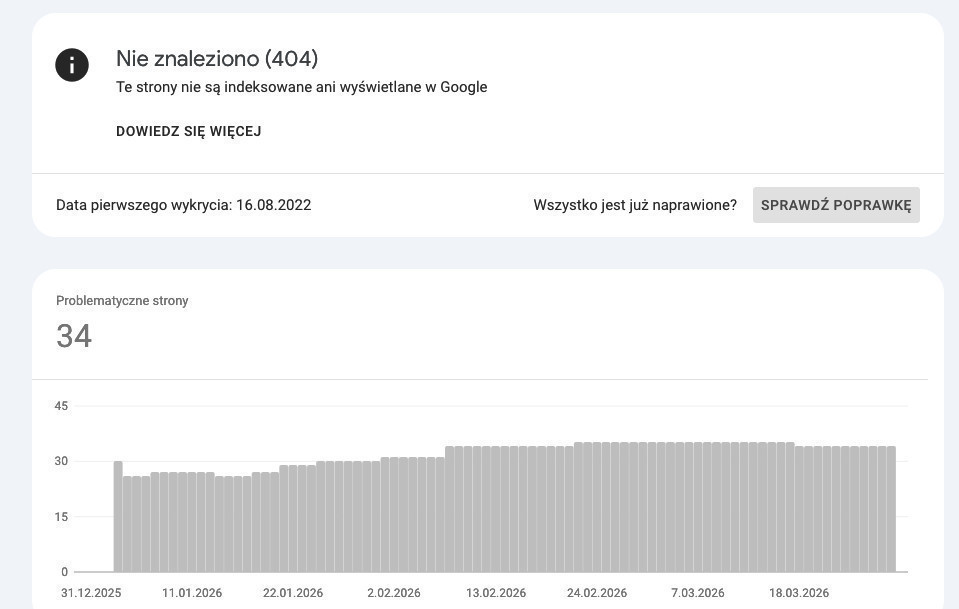
410 — kiedy zasób nie wróci
Kod 410 to rodzaj twardszego 404. Serwer informuje, że zasób nie tylko nie istnieje teraz, ale nie będzie istniał w przyszłości. Różnica w zachowaniu Googlebot jest zauważalna: adresy ze statusem 410 są usuwane z indeksu szybciej, bez wielokrotnych powrotów weryfikacyjnych.
W praktyce 410 przydaje się wszędzie tam, gdzie zależy nam na szybkiej deindeksacji — na przykład przy usuwaniu stron niskiej jakości po algorytmicznej korekcie albo przy zamykaniu segmentu serwisu, który nie powinien już być widoczny w wyszukiwarce. Jeśli ktoś usuwa kilkaset stron i chce, żeby Googlebot jak najszybciej o nich zapomniał, 410 jest właściwym wyborem.
403 — bot, który nie ma wejścia
Kod 403 oznacza odmowę dostępu. Serwer rozumie żądanie, ale nie zamierza go obsługiwać dla danego klienta. Dla Googlebot to sygnał, że nie ma uprawnień do pobrania treści.
Celowe blokowanie Googlebot przez 403 jest jak najbardziej prawidłowe — panel administracyjny, środowisko stagingowe, wewnętrzne narzędzia. Problem pojawia się tam, gdzie 403 pojawia się niezamierzenie: błędna konfiguracja .htaccess, zbyt agresywny WAF klasyfikujący Googlebot jako podejrzany ruch, albo rate limiting, który traktuje robota tak samo jak zwykłego użytkownika i po kilkunastu żądaniach na minutę blokuje jego IP.
Strony, które przez dłuższy czas zwracają 403, mogą wypadać z indeksu podobnie jak przy 404, jeśli odpowiedź utrzymuje się długoterminowo. Serwer odpowiada konsekwentnie odmową, Googlebot po kilku próbach traci zainteresowanie.
429 — serwer prosi o oddech
Kod 429 informuje, że klient wysyła zbyt wiele żądań w zbyt krótkim czasie. To instrukcja dla Googlebot: zwolnij.
Serwis, który regularnie zwraca 429 robotowi indeksującemu, może doprowadzić do obniżenia częstotliwości crawlowania — często na poziomie całej domeny. Nie poszczególnych adresów — domeny. To z kolei przekłada się na wolniejsze odkrywanie nowych treści, wolniejsze aktualizacje indeksu i potencjalnie na słabszą widoczność świeżo opublikowanych materiałów.
Rozwiązanie jest techniczne: sprawdzić konfigurację rate limitingu, whitelistować zakresy IP Googlebot (Google publikuje je w pliku JSON na developers.google.com) i — jeśli 429 wynika z faktycznego przeciążenia serwera — rozważyć, czy infrastruktura jest adekwatna do skali crawlowania. W Search Console jest też opcja ręcznego ograniczenia intensywności crawlowania, z której warto skorzystać, gdy serwer ma rzeczywiste problemy wydajnościowe.
Klasa 5xx — tutaj naprawdę może boleć
Błędy 5xx różnią się od 4xx jedną fundamentalną kwestią: zasób może istnieć, być wartościowy i mieć dobre rankingi — problem leży wyłącznie w infrastrukturze. To sprawia, że Googlebot zachowuje się ostrożniej i nie usuwa stron z indeksu tak szybko jak przy 4xx. Ale to nie znaczy, że brak konsekwencji.
500 — awaria bez szczegółów
Kod 500 to ogólny błąd serwera — coś poszło nie tak, ale serwer nie precyzuje co. Dla Googlebot to sygnał niejednoznaczny. Bot zakłada, że awaria może być przejściowa, wraca do adresu po jakimś czasie i liczy, że sytuacja się unormuje.
Dopóki 500 jest krótkotrwały `
Jeśli występuje kilka minut, góra kilka godzin — konsekwencje SEO są zazwyczaj minimalne. Ale jeśli błąd utrzymuje się przez kilka dni, Google może ograniczyć widoczność stron lub tymczasowo je wycofać z wyników. Po zakończeniu awarii rankingi wracają, ale może to potrwać od kilku dni do kilku tygodni — zależnie od tego, jak długo strony były niedostępne i jak duży autorytet zdążyły wcześniej zbudować.
502 — pośrednik bez upstream
Kod 502 pojawia się, gdy serwer pośredniczący — reverse proxy, load balancer, CDN — nie dostaje odpowiedzi od serwera docelowego. PHP-FPM przestał odpowiadać, połączenie między CDN a serwerem origin padło, serwer aplikacji jest przeciążony. Dla użytkownika: strona nie działa. Dla Googlebot: identyczna sytuacja.
Szczególna cecha 502 to jego masowy charakter. Nie mamy do czynienia z jedną niedostępną podstroną — zazwyczaj nie działa cała domena albo jej duży segment. Kilkugodzinna awaria 502 w logach serwera powinna trafiać na samą górę listy priorytetów, nie dlatego że użytkownicy narzekają, ale właśnie dlatego, że może kosztować tygodnie odbudowy rankingów.
503 — najbezpieczniejszy błąd serwera — szczególnie jeśli towarzyszy mu Retry-After
Kod 503 jest wyjątkowy. To jedyna odpowiedź serwera z klasy 5xx, którą Google traktuje z cierpliwością — ale tylko wtedy, gdy serwer wysyła ją razem z nagłówkiem Retry-After.
Nagłówek Retry-After informuje Googlebot, kiedy serwis będzie z powrotem dostępny. Bot respektuje tę informację i wraca po wskazanym czasie, nie traktując niedostępności jako permanentnej. To jest rekomendowany przez Google sposób na przeprowadzenie prac konserwacyjnych bez ryzyka deindeksacji:
HTTP/1.1 503 Service Unavailable
Retry-After: 3600
Powyższy przykład mówi: wróć za godzinę. Googlebot wróci za godzinę. Strony zostają w indeksie.
Bez nagłówka Retry-After sytuacja wygląda gorzej. Bot nie wie, kiedy serwis wróci, więc zachowuje się podobnie jak przy 500 — czyli z każdą kolejną nieskuteczną próbą obniża priorytet indeksowania danej domeny. Warto też pamiętać, że 503 w kółko w nocy — bo codziennie o tej samej porze odpala się backup i serwer siada na kilkanaście minut — to z pozoru błahostka, która po tygodniach regularnego powtarzania może wyraźnie obniżyć częstotliwość crawlowania.
504 — timeout, czyli czekanie bez końca
Kod 504 to sytuacja, gdy serwer proxy czeka na odpowiedź od upstream dłużej niż wynosi skonfigurowany timeout i odpuszcza. Dla użytkownika strona kręci kółeczko, a potem wyrzuca błąd. Dla Googlebot — identycznie.
Regularne 504 w logach to zazwyczaj sygnał problemów wydajnościowych po stronie aplikacji: ciężkie zapytania do bazy danych bez indeksowania, brak cache'owania generowanych odpowiedzi, albo po prostu serwer, który nie jest w stanie obsłużyć liczby równoczesnych żądań. To problem, który dotyka zarówno użytkowników (słaby UX), Core Web Vitals (wysoki TTFB) jak i crawl budget Googlebot.
Pozorny błąd 404 — największy problem, o którym mało kto mówi
Soft 404, czyli miękki błąd 404, to strona, która wygląda jak błąd — pusta kategoria, produkt wycofany z oferty, wyniki wyszukiwania bez odpowiedzi — ale serwer zwraca dla niej kod 200 OK. Z punktu widzenia protokołu HTTP wszystko jest w porządku. Z punktu widzenia SEO to potencjalnie jeden z droższych problemów w serwisie.
Google musi samodzielnie wykrywać soft 404 poprzez analizę treści strony, bez wyraźnego sygnału w postaci kodu błędu. Takie strony zajmują miejsce w indeksie, pochłaniają crawl budget i mogą rozmywać sygnały jakościowe całej domeny. W dużych sklepach e-commerce problem bywa gigantyczny — setki tysięcy podstron z komunikatem „Brak produktów w tej kategorii" albo „Ten produkt jest niedostępny", wszystkie z kodem 200, wszystkie w indeksie.
Jak je znaleźć? Raport „Strony" w Search Console, zakładka „Wykluczone", pozycja „Pozorny błąd 404" — to punkt startowy, ale nie wyczerpuje problemu, bo Google nie wykrywa ich wszystkich. 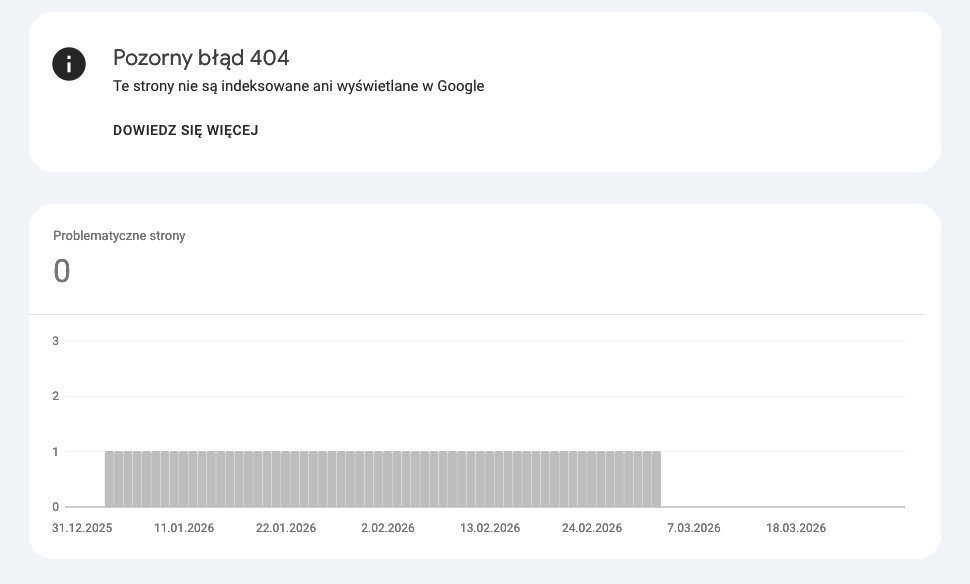
Co z nimi zrobić, zależy od konkretnego przypadku. Strona kategorii bez produktów, która nigdy nie wróci — powinna zwracać 404 albo być przekierowana na nadrzędną kategorię. Strona produktu wycofanego, do której prowadzą linki zewnętrzne — warto rozważyć pozostawienie jej z informacją o alternatywach albo przekierowanie na podobny produkt. Blank page zwracająca 200 OK bez żadnej treści — 410 i tyle:)
Crawl budget — jak błędy serwera zjadają zasób, którego nie widać
Crawl budget to liczba adresów URL, które Googlebot jest gotowy odwiedzić w danym serwisie w określonym przedziale czasu. Dla małych serwisów temat jest prawie nieistotny — robot indeksuje wszystko w dni lub tygodnie. Dla dużych serwisów z milionami podstron to zasób, który trzeba aktywnie zarządzać, bo jego marnotrawstwo bezpośrednio przekłada się na wolniejszą indeksację.
Błędy serwera marnują crawl budget w kilku mechanizmach. Masowe 404 generowane przez parametry URL, błędy paginacji czy zepsute linki wewnętrzne sprawiają, że Googlebot spędza czas na adresach, które nic nie zawierają — zamiast na odkrywaniu nowych treści. Niestabilne odpowiedzi 5xx „uczą" Google, że domena jest zawodna, co może skutkować obniżeniem globalnej częstotliwości crawlowania — nie tylko dla problematycznych adresów, ale dla całego serwisu.
Wolne odpowiedzi serwera to osobna historia, choć technicznie nie jest to błąd HTTP. Googlebot uwzględnia czas odpowiedzi przy planowaniu kolejnych wizyt. Serwer, który regularnie odpowiada w 3–5 sekund, będzie odwiedzany rzadziej niż serwer z czasem odpowiedzi poniżej 300 ms. Szczególnie widać to w logach serwisów, które przeszły na hostingi VPS z ograniczonymi zasobami bez równoczesnej optymalizacji aplikacji.
Logi serwera — gdzie naprawdę widać, co się dzieje
Search Console to świetne narzędzie, ale pokazuje wyłącznie to, co Google zdecydowało się udostępnić: dane z opóźnieniem, próbkę żądań, kody statusu po stronie Google. Logi serwera pokazują pełny obraz z perspektywy samego serwera — i często te dwa obrazy się rozmijają.
Przy analizie logów pod kątem SEO interesują nas przede wszystkim cztery rzeczy: proporcje kodów statusu zwracanych Googlebotowi, czasy odpowiedzi serwera na żądania robota, częstotliwość i wzorzec crawlowania poszczególnych sekcji serwisu oraz obecność podejrzanych user agentów podszywających się pod Googlebot.
Ten ostatni punkt jest niedoceniany. Pojawienie się w logach ciągu „Googlebot" w polu user agenta nie oznacza, że to naprawdę Google. Weryfikacja autentyczności Googlebot wymaga dwóch kroków: odwrotnego DNS lookup dla adresu IP (wynik powinien kończyć się na .googlebot.com albo google.com) oraz forward DNS lookup z otrzymanej nazwy, który powinien zwrócić z powrotem oryginalne IP. Jeśli oba kroki się zgadzają — to naprawdę Google. Jeśli nie — ktoś podszywa się pod Googlebot, co w najlepszym razie oznacza marnowanie zasobów serwera, a w gorszym — celowe skanowanie serwisu.
Migracja URL i inne klasyczne scenariusze
Migracja serwisu albo restrukturyzacja URL to najczęstszy powód masowych 404 w SEO. Każdy adres, który zmienia swoją strukturę bez przekierowania 301, generuje 404 i traci skumulowany autorytet linkowy. W dużych serwisach z kilkudziesięcioletnim profilem linkowym może to być autentycznie poważna strata. Właściwe przygotowanie do migracji zaczyna się od pełnego crawla serwisu i eksportu wszystkich aktywnych adresów URL, a kończy na monitorowaniu Search Console przez co najmniej kilka miesięcy po wdrożeniu.
Innym scenariuszem, który zaskakuje wiele sklepów e-commerce, jest sezonowe przeciążenie serwera — Black Friday, Boże Narodzenie, wyprzedaże. Serwer, który przez jedenaście miesięcy w roku radzi sobie bez zarzutu, w szczycie ruchu zaczyna serwować 503 i 502 dla połowy żądań. Jeśli Googlebot trafi na falę 5xx właśnie wtedy, rankingi mogą obniżyć się dokładnie w momencie, gdy ruch organiczny jest najcenniejszy. Testy obciążeniowe przed sezonem, CDN dla statycznych zasobów i gotowość do szybkiego skalowania infrastruktury to nie tylko operacyjna higiena — to element strategii SEO.
Ataki DDoS to osobna kategoria, bo trudno je przewidzieć. Kilkugodzinna niedostępność to zazwyczaj problem, który Googlebot przeżyje bez długotrwałych konsekwencji. Niedostępność trwająca dobę lub dłużej — zwłaszcza jeśli powtarza się kilkukrotnie — może wymagać tygodni na odbudowę rankingów. Po odparciu ataku warto sprawdzić w Search Console, jak wyglądały kody statusu widziane przez Google podczas niedostępności i monitorować widoczność przez kolejne kilka tygodni.
TTFB i Core Web Vitals — powolny serwer to też problem SEO
Nie wszystkie problemy serwera pojawiają się jako błędy HTTP. Serwer może zwracać 200 OK dla każdego żądania, a i tak niszczyć pozycje — jeśli robi to zbyt wolno.
TTFB, czyli czas do pierwszego bajtu, to czas od wysłania żądania HTTP do odebrania pierwszego bajtu odpowiedzi. Wysoki TTFB bezpośrednio przekłada się na LCP (Largest Contentful Paint) — jeden z trzech wskaźników Core Web Vitals uwzględnianych przez Google jako sygnał rankingowy od 2021 roku. Serwer odpowiadający w 600–800 ms utrudnia osiągnięcie dobrego LCP nawet przy perfekcyjnie zoptymalizowanym frontendzie. Żadna kompresja obrazów ani lazy loading nie nadrobi sekundowego opóźnienia po stronie serwera.
Optymalizacja TTFB to temat na osobny artykuł, ale kluczowe kierunki działania to: cache'owanie na poziomie serwera (Varnish, Nginx FastCGI Cache, Redis), optymalizacja zapytań do bazy danych i ich wyników, CDN dla zasobów statycznych i — jeśli nic innego nie pomaga — dopasowanie infrastruktury do faktycznej skali ruchu.
Co naprawiać najpierw
Błędy serwera różnią się pilnością. Masowe 500 albo 502 obejmujące całą domenę to incydent krytyczny — każda minuta przekłada się bezpośrednio na widoczność w wyszukiwarce, nie tylko na utratę ruchu użytkowników. 403 blokujące Googlebot na stronach, które mają być indeksowane, i 404 po migracji bez przekierowań to kategoria wymagająca reakcji w ciągu godzin lub doby.
Niżej w kolejce, choć nadal ważne: regularne 504 sugerujące problemy wydajnościowe aplikacji, masowe soft 404 w dużych serwisach e-commerce, 429 ograniczające crawlowanie. To problemy, które można rozwiązać w ramach planowych prac, ale odkładanie ich na długie tygodnie ma swoje konsekwencje.
Warto też pamiętać, że nie wszystkie 404 wymagają natychmiastowej reakcji. Pojedyncze stare adresy bez linków zewnętrznych i bez historycznego ruchu można bezpiecznie zignorować albo obsłużyć przy okazji kolejnego sprintu developerskiego. Ważne, żeby umieć odróżnić, które 404 naprawdę bolą, a które są po prostu bałaganem na liście raportów.
Serwer rozmawia z Googlebotom w języku kodów HTTP. Warto rozumieć ten język lepiej niż algorytm — bo to jedyny sposób, żeby wiedzieć z wyprzedzeniem, kiedy ta rozmowa zaczyna iść w złym kierunku.
 Bartosz Cymes
Bartosz Cymes